Generating & Modelling Cryptography
CryptoKnight is a framework I recently released which follows the methodology described in my publication for synthesizing a scalable dataset of cryptographic primitives to feed a unique Convolutional Neural Network. In effect, this allows us to generate and model a substantial amount of data to quickly identify cryptographic algorithms (such as AES, RSA, RC4, or MD5) in reference binary executables. By safely learning this statistical representation, malware analysts can efficiently compare it against crypto-ransomware samples in a controlled environment.

The aim of this post is to introduce newcomers to the toolkit; potential malware analysts, reverse engineers or even collaborators / maintainers!
Getting Started
The first thing that you’ll need to do is download the source code:
git clone git@github.com:AbertayMachineLearningGroup/CryptoKnight.git
Before you can do anything else, you’ll also need to install the following dependencies on your local machine (you may need admin privileges):
apt-get install python-pip python-tk gcc g++ libssl-dev
You don’t necessarily need to install python-pip if you manage Python libraries some other way, but it’s well documented and easy to use. The TkInter package (python-tk) is only required for Matplotlib’s graphing, so it can also be dropped if unwanted. However, the remaining packages are essential for binary synthesis and reverse engineering, so you’ll probably want to keep them! Other Python dependencies are listed in the requirements.txt file; which pip can automatically read, download and install:
pip install -r requirements.txt
Once everything else is in place, let’s download Intel’s PIN Tool and compile our new toolkit:
python knight.py --setup
That’s it, you’ve now setup your own cryptographic analysis workstation! We’re now ready to generate some data and classify some algorithms.
Generation
Whether you’re importing new cryptographic signatures based on the format specification, feature engineering or just interested in the synthesis process, you’ll want to start here! However, if you just want to start testing some ransomware (against the pre-trained model) then skip down to the next section. If you want to train a new model instead, the repository also contains a bunch of datasets.
I’ve strived to simplify this process as much as possible. Thankfully, the procedure can now be initiated with just one command:
python crypto.py -d scale
This generates a new data distribution based on the scale which is split into training and testing (75/25) which helps our model to learn better and hopefully generalize in the future. In the accordingly named sub-directories, the framework instantiates the primitives from our pool and procedurally generates an equivalent number of binaries which are statically linked to the OpenSSL C library. Each application is then run through the specialized tracing tool to extract feature matrices based on a pre-defined selection of opcodes. Once data extraction finally completes, CryptoKnight will automatically learn the model. We use a unique Dynamic Convolutional Neural Network to trickle through our arbitrary sized matrices, which hopefully picks the best features that define cryptographic activity. If the model doesn’t perform as expected, we can tune it:
python crypto.py --tune
This performs a hyperparameter grid search to locate optimal settings for the task, but just watch you don’t overfit the data!
Analysis
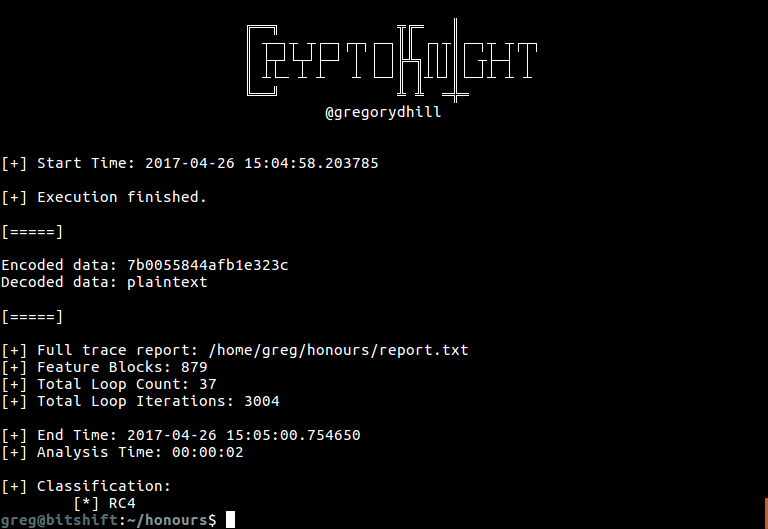
With a trained model, we can now test a new sample. Suppose we have a binary called hash.exe which takes the MD5 of a file or string. Let’s ask CryptoKnight to attack it!
python knight.py --predict hash.exe
The program will be started in a sub-shell, attached to our dynamic instrumentation tool. This will carefully trace the application, output a sample listing and report other metrics. It will then call the model to analyze the sample and output the strongest correlation, which in this case should be MD5.
Another feature was built in with the sole purpose of evaluation in the original paper. The flag –evaluate takes a relative path to a validation set, imports the data, classifies it, then outputs a confusion matrix. Academics and researchers may want to use this to compare their own methodologies!
Anyway, that should be more than enough information to help you get stuck in. Thanks for reading, if you have any questions feel free to ping me on twitter @gregorydhill. Contributions are also welcome, so please take a look at the issues on GitHub.